A phrase you’ll often hear is that everything in Python is an object, and every object has a type. This points to the importance of data types in Python. However, often what an object can do is more important than what it is. So, it’s useful to discuss categories of data types and one of the main categories is Python’s sequence.
In this tutorial, you’ll learn about:
- Basic characteristics of a sequence
- Operations that are common to most sequences
- Special methods associated with sequences
- Abstract base classes
SequenceandMutableSequence - User-defined mutable and immutable sequences and how to create them
This tutorial assumes that you’re familiar with Python’s built-in data types and with the basics of object-oriented programming.
Get Your Code: Click here to download the free sample code that you’ll use to learn about Python sequences in this comprehensive guide.
Take the Quiz: Test your knowledge with our interactive “Python Sequences: A Comprehensive Guide” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Python Sequences: A Comprehensive GuideIn this quiz, you'll test your understanding of sequences in Python. You'll revisit the basic characteristics of a sequence, operations common to most sequences, special methods associated with sequences, and how to create user-defined mutable and immutable sequences.
Building Blocks of Python Sequences
It’s likely you used a Python sequence the last time you wrote Python code, even if you don’t know it. The term sequence doesn’t refer to a specific data type but to a category of data types that share common characteristics.
Characteristics of Python Sequences
A sequence is a data structure that contains items arranged in order, and you can access each item using an integer index that represents its position in the sequence. You can always find the length of a sequence. Here are some examples of sequences from Python’s basic built-in data types:
>>> # List
>>> countries = ["USA", "Canada", "UK", "Norway", "Malta", "India"]
>>> for country in countries:
... print(country)
...
USA
Canada
UK
Norway
Malta
India
>>> len(countries)
6
>>> countries[0]
'USA'
>>> # Tuple
>>> countries = "USA", "Canada", "UK", "Norway", "Malta", "India"
>>> for country in countries:
... print(country)
...
USA
Canada
UK
Norway
Malta
India
>>> len(countries)
6
>>> countries[0]
'USA'
>>> # Strings
>>> country = "India"
>>> for letter in country:
... print(letter)
...
I
n
d
i
a
>>> len(country)
5
>>> country[0]
'I'
Lists, tuples, and strings are among Python’s most basic data types. Even though they’re different types with distinct characteristics, they have some common traits. You can summarize the characteristics that define a Python sequence as follows:
- A sequence is an iterable, which means you can iterate through it.
- A sequence has a length, which means you can pass it to
len()to get its number of elements. - An element of a sequence can be accessed based on its position in the sequence using an integer index. You can use the square bracket notation to index a sequence.
There are other built-in data types in Python that also have all of these characteristics. One of these is the range object:
>>> numbers = range(5, 11)
>>> type(numbers)
<class 'range'>
>>> len(numbers)
6
>>> numbers[0]
5
>>> numbers[-1]
10
>>> for number in numbers:
... print(number)
...
5
6
7
8
9
10
You can iterate through a range object, which makes it iterable. You can also find its length using len() and fetch items through indexing. Therefore, a range object is also a sequence.
You can also verify that bytes and bytearray objects, two of Python’s built-in data structures, are also sequences. Both are sequences of integers. A bytes sequence is immutable, while a bytearray is mutable.
Special Methods Associated With Python Sequences
In Python, the key characteristics of a data type are determined using special methods, which are defined in the class definitions. The special methods associated with the properties of sequences are the following:
.__iter__(): This special method makes an object iterable using Python’s preferred iteration protocol. However, it’s possible for a class without an.__iter__()special method to create iterable objects if the class has a.__getitem__()special method that supports iteration. Most sequences have an.__iter__()special method, but it’s possible to have a sequence without this method..__len__(): This special method defines the length of an object, which is normally the number of elements contained within it. Thelen()built-in function calls an object’s.__len__()special method. Every sequence has this special method..__getitem__(): This special method enables you to access an item from a sequence. The square brackets notation can be used to fetch an item. The expressioncountries[0]is equivalent tocountries.__getitem__(0). For sequences,.__getitem__()should accept integer arguments starting from zero. Every sequence has this special method. This method can also ensure an object is iterable if the.__iter__()special method is missing.
Therefore, all sequences have a .__len__() and a .__getitem__() special method and most also have .__iter__().
However, it’s not sufficient for an object to have these special methods to be a sequence. For example, many mappings also have these three methods but mappings aren’t sequences.
A dictionary is an example of a mapping. You can find the length of a dictionary and iterate through its keys using a for loop or other iteration techniques. You can also fetch an item from a dictionary using the square brackets notation.
This characteristic is defined by .__getitem__(). However, .__getitem__() needs arguments that are dictionary keys and returns their matching values. You can’t index a dictionary using integers that refer to an item’s position in the dictionary. Therefore, dictionaries are not sequences.
Slicing in Python Sequences
All sequences support indexing using an integer that represents the item’s position within the sequence. This requirement is part of the definition of a Python sequence.
Most sequences also support slicing, which is often closely associated with indexing. You can slice most sequences to access a subset of the elements. All of the sequences you’ve encountered so far can be sliced:
>>> countries = ["USA", "Canada", "UK", "Norway", "Malta", "India"]
>>> countries[1:4]
['Canada', 'UK', 'Norway']
>>> countries = "USA", "Canada", "UK", "Norway", "Malta", "India"
>>> countries[1:4]
('Canada', 'UK', 'Norway')
>>> country = "India"
>>> country[1:4]
'ndi'
>>> numbers = range(5, 11)
>>> numbers[1:4]
range(6, 9)
In all four examples, you extract the items from index 1 up to but excluding index 4. The result is a data structure of the same type as the original one containing the subset of elements.
Slicing also depends on the .__getitem__() special method in these data types and other sequences. Typically, .__getitem__() can accept either an integer or a slice object. The special method’s behavior depends on whether it’s passed an integer or a slice.
However, it’s possible to have sequences that don’t support slicing. The deque data type in Python’s collections module is an example of this. First, you can confirm that a deque is a sequence:
>>> from collections import deque
>>> countries = deque(["USA", "Canada", "UK", "Norway", "Malta", "India"])
>>> for country in countries:
... print(country)
...
USA
Canada
UK
Norway
Malta
India
>>> len(countries)
6
>>> countries[0]
'USA'
You can iterate through a deque, get its length, and index it. Therefore, it’s a sequence but you can’t slice a deque:
>>> countries[1:4]
Traceback (most recent call last):
...
TypeError: sequence index must be integer, not 'slice'
The TypeError shows that a deque can only be indexed using an integer, and a slice can’t be used in the square brackets. Deques are optimized to provide efficient access at either the beginning or the end of the data structure. Therefore, slicing would be inefficient and generally not the intended use for deques.
Although most sequences support slicing, you shouldn’t assume that all of them do.
Concatenating Sequences
Most sequences can be added to another sequence of the same type. For example, you can combine two lists, or you can add a tuple to another tuple:
>>> [1, 2, 3] + [4, 5, 6]
[1, 2, 3, 4, 5, 6]
>>> (1, 2, 3) + (4, 5, 6)
(1, 2, 3, 4, 5, 6)
The output is a sequence of the same type as the original ones. However, in general, you can’t add sequences of different types:
>>> [1, 2, 3] + (4, 5, 6)
Traceback (most recent call last):
...
TypeError: can only concatenate list (not "tuple") to list
You get an error when you try to add a list and a tuple. Many sequences can be concatenated in this way, but not all of them. Here’s an example of a sequence that can’t be concatenated:
>>> range(10) + range(10, 20, 2)
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +: 'range' and 'range'
You learned earlier that a range object is a sequence. However, it requires items that follow specific patterns that can be represented by a start, stop, and step value. For this reason, a range object can only represent a series of numbers with regular increments between them.
In the example above, the first range object represents the numbers from one to nine. The second range object represents the numbers from ten to nineteen but in steps of two. Therefore, you can’t represent the concatenation of these two series using a range object, which must be defined by its start, stop, and step values.
Another difference in behavior between sequences is highlighted when using the augmented assignment operators, such as +=, on mutable and immutable data types:
>>> numbers_list = [1, 2, 3]
>>> id(numbers_list)
4331793920
>>> numbers_list += [4, 5, 6]
>>> numbers_list
[1, 2, 3, 4, 5, 6]
>>> id(numbers_list)
4331793920
The extended list is the same object as the original numbers_list. The value returned by the built-in id() function is the same before and after the augmented assignment operation. However, the behavior is different when using tuples:
>>> numbers_tuple = 1, 2, 3
>>> id(numbers_tuple)
4331564032
>>> numbers_tuple += 4, 5, 6
>>> numbers_tuple
(1, 2, 3, 4, 5, 6)
>>> # This is a new tuple object
>>> id(numbers_tuple)
4331414688
The augmented addition assignment applied to a list, which is a mutable sequence, extends the same object with the new values. However, tuples are immutable, which leads the += operator to create a new object.
Comparing Values With Sequences
Built-in sequences support value comparisons such as equality and greater than or less than comparisons. However, only sequences of the same type can be compared:
>>> countries_list = ["USA", "Canada", "UK", "Norway", "Malta", "India"]
>>> countries_tuple = "USA", "Canada", "UK", "Norway", "Malta", "India"
>>> countries_list == countries_tuple
False
>>> countries_list == countries_list
True
When two sequences of the same type are compared to check if one is greater than or less than the other, the first non-equal value determines the outcome:
>>> numbers = [1, 2, 3, 4, 5]
>>> more_numbers = [1, 2, 2, 10, 20]
>>> numbers > more_numbers
True
Both lists have the same first two values. However, the third item in numbers is larger than the third item in more_numbers. Therefore, numbers is greater than more_numbers even though the remaining integers in more_numbers are larger.
If the items in a sequence are equal to items with matching indices in another sequence, but one sequence has more items, the sequence with more items is considered greater:
>>> numbers = [1, 2, 3]
>>> more_numbers = [1, 2]
>>> numbers > more_numbers
True
>>> numbers = [1, 0, 3]
>>> numbers > more_numbers
False
However, in the second example, numbers[1] is 0, which is smaller than more_numbers[1]. As a result, more_numbers is greater than numbers.
Creating User-Defined Python Sequences
You’ve learned about features that define sequences, including the special methods they have in common. You can also use this knowledge to create user-defined classes that are sequences.
In this section, you’ll define a class called ShapePoints, which contains a number of points that define the vertices of a shape. You can create a file named shape.py:
shape.py
class ShapePoints:
def __init__(self, points):
self.points = list(points)
The class’s .__init__() includes a points parameter. You pass a sequence of coordinate pairs when you create a ShapePoints object, such as a list of tuples. You then cast the input sequence as a new list object to avoid some mutability issues and assign it to the data attribute .points.
Now you can create instances of this new class and explore its features through a REPL session:
>>> from shape import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle.points
[(100, 100), (-200, 100), (-200, -200)]
You import the class ShapePoints and create an instance with three points. The shape represents a triangle, and the data attribute .points contains the three tuples with the points’ coordinates.
You can make a few more additions to the basic setup for this class before you start exploring its sequence features. This class is used for closed shapes, which means the last point should be identical to the first. You can ensure this is the case by adding an extra point that’s equal to the first if it doesn’t already exist. You also add a docstring with a basic description of the class:
shape.py
class ShapePoints:
"""
A ShapePoints object represents a collection of points
Attributes:
- points: sequence of points, where each point is a
tuple (x, y)
"""
def __init__(self, points):
self.points = list(points)
if self.points[0] != self.points[-1]:
self.points.append(self.points[0])
A ShapePoints object is always closed. Therefore, you add the first point to the end of the list .points if the first and last points aren’t already equal. This step ensures the first and last vertices are the same. As you explore this class in this tutorial, you’ll make the necessary changes to keep the shape closed even when you modify the points in the shape.
Next, you add a .__repr__() special method to define a string representation for the class:
shape.py
class ShapePoints:
"""
A ShapePoints object represents a collection of points
Attributes:
- points: sequence of points, where each point is a
tuple (x, y)
"""
def __init__(self, points):
self.points = list(points)
if self.points[0] != self.points[-1]:
self.points.append(self.points[0])
def __repr__(self):
return f"ShapePoints({self.points})"
The .__repr__() special method ensures a meaningful output in all situations when you display the object. It’s always a good idea to include this special method in user-defined classes.
Note: You’ll need to start a new REPL session each time you make changes to the class definition in shapes.py. You can’t write the import statement again in the same REPL session, as this won’t import the updated class. It’s also possible to use importlib from the standard library to reload a module, but it’s easier to start a new REPL.
In a new REPL session, you can create the ShapePoints object again and display the object directly instead of its .points attribute:
>>> from shape import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle
ShapePoints([(100, 100), (-200, 100), (-200, -200), (100, 100)])
The output shows the string representation for the ShapePoints object, which includes four points since it’s a closed shape and the first point is repeated at the end.
Say you would like a ShapePoints object to be a sequence. However, it doesn’t meet any of the three requirements at the moment. You can try to iterate through triangle:
>>> for point in triangle:
... print(point)
...
Traceback (most recent call last):
...
TypeError: 'ShapePoints' object is not iterable
When you try to iterate through triangle, Python raises an exception since the object is not iterable. You can try to find the length of the object:
>>> len(triangle)
Traceback (most recent call last):
...
TypeError: object of type 'ShapePoints' has no len()
Passing a ShapePoints object to len() also doesn’t work and leads to another TypeError. The error states that the object has no length. Finally, you can attempt to index the object to retrieve one of its elements:
>>> triangle[0]
Traceback (most recent call last):
...
TypeError: 'ShapePoints' object is not subscriptable
Attempting to index triangle completes the trio of TypeErrors. The error now states that a ShapePoints object is not subscriptable, which means you can’t use the square brackets notation to access values within it.
Making the Class Indexable Using .__getitem__()
You can add the .__getitem__() special method to the class in shape.py to make it subscriptable. However, if you want a ShapePoints object to be a sequence, this special method needs to accept integers and fetch items based on their position:
shape.py
class ShapePoints:
# ...
def __getitem__(self, index):
return self.points[index]
You rely on the fact that the .points data attribute is a list, which also makes it a sequence. Now you can check whether indexing works in a new REPL session:
>>> from shape import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle[0]
(100, 100)
A ShapePoints object is now indexable since you can use an integer to fetch an item based on its position. Since you’re using the sequence features of the list data type in .points, you can also slice a ShapePoints object:
>>> triangle[:2]
[(100, 100), (-200, 100)]
This notation returns a slice of the ShapePoints object, which in this case is the slice that includes the first and second elements of triangle.
Adding the .__getitem__() special method makes a ShapePoints object indexable. However, it also enables other features that use this method. For example, you can now iterate through the ShapePoints object:
>>> for point in triangle:
... print(point)
...
(100, 100)
(-200, 100)
(-200, -200)
(100, 100)
This code no longer raises a TypeError, as it did earlier in this tutorial. Instead, it prints the tuples with the shape’s points, including the additional final point that’s equal to the first point since the shape is closed.
Later in this tutorial, you’ll update the class to make it iterable using another special method, .__iter__(). Using .__iter__() is the preferred option to make objects iterable in modern Python.
You can check whether an element is a member of triangle, and you can also sort the items in the shape:
>>> (100, 100) in triangle
True
>>> sorted(triangle)
[(-200, -200), (-200, 100), (100, 100), (100, 100)]
The code outputs True to show that (100, 100) is a member of the ShapePoints object. It also outputs a list with the points sorted following the default sorting rules for tuples. Note that sorted() returns a list of tuples and not a ShapePoints object.
Adding .__getitem__() adds several features to the ShapePoints class. However, there are other special methods dedicated to these features, which you’ll explore later.
You still can’t get the length of a ShapePoints object. In the next section, you’ll add another special method to define the length of an object.
Making the Class Sized Using .__len__()
A sized object is one that has a defined length, which you can access using the built-in len() function. To make a ShapePoints object sized, you can add the .__len__() special method to the class definition. This method must return an integer.
You’ll need to decide whether you want the length of the ShapePoints object to include all the values in .points or whether you want to exclude the final pair of coordinates from the count so that the length represents the number of vertices. This version defines the length as the number of points in the shape:
shape.py
class ShapePoints:
# ...
def __len__(self):
return len(self.points) - 1
Since .points is a list and has a length, you subtract one from the length of the list to account for the repeated point at the end of .points. You can now call len(triangle) and get the number of points in the shape. Remember, you’ll need to start a new REPL session to explore the updated class:
>>> from shape import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> len(triangle)
3
The .__len__() special method also provides the object with a definition of truthiness. You can convert any object to a True or False value using the built-in bool(). By default, an object is truthy, which means it’s converted to True when passed to bool().
However, a sized object is truthy if it has a non-zero length and falsy if it’s empty. You can convert triangle into a Boolean using bool():
>>> bool(triangle)
True
To confirm that the object follows the truthiness rules for sequences, you’ll need to create an empty ShapePoints object:
>>> another_shape = ShapePoints([])
Traceback (most recent call last):
...
if self.points[0] != self.points[-1]:
~~~~~~~~~~~^^^
IndexError: list index out of range
This step highlights a bug in your code that occurs when there are no points in the shape. Since the shape is closed, you duplicate the first point to place it at the end of the sequence. However, points[0] raises an error when the list is empty. You can update the if statement in the class’s .__init__() method to account for this case:
shape.py
class ShapePoints:
# ...
def __init__(self, points):
self.points = list(points)
if points and self.points[0] != self.points[-1]:
self.points.append(self.points[0])
# ...
In the expression in the if statement, if points is empty, it evaluates as falsy. The and expression is evaluated lazily, which means that if points is falsy, the rest of the and expression is ignored and won’t raise an exception.
You can now create an empty ShapePoints object in a new REPL to confirm that an empty object is falsy:
>>> from shape import ShapePoints
>>> another_shape = ShapePoints([])
>>> bool(another_shape)
Traceback (most recent call last):
...
ValueError: __len__() should return >= 0
However, this raises yet another exception. The .__len__() special method subtracts one from the length of .points, but the value returned by .__len__() can’t be negative since a negative length is invalid. You can update .__len__() to account for this scenario:
shape.py
class ShapePoints:
# ...
def __len__(self):
if self.points:
return len(self.points) - 1
return 0
If .points is not empty, you subtract the last value and return the result. If there are no values in .points, you return zero. A new REPL session confirms that an empty ShapePoints object is falsy:
>>> from shape import ShapePoints
>>> another_shape = ShapePoints([])
>>> bool(another_shape)
False
You can comment out the .__len__() definition in shape.py and run the same code in a new REPL. Without the .__len__() special method, the object is always truthy.
Making the Class Iterable Using .__iter__()
The ShapePoints object is already a sequence since it’s iterable, indexable, and has a length. However, it’s preferable to use the .__iter__() iteration protocol to make an object iterable since this offers more compatibility across different types of iteration and can provide more efficient iteration.
You can define this special method and rely on the list in .points to provide the iteration:
shape.py
class ShapePoints:
# ...
def __iter__(self):
return iter(self.points)
The .__iter__() special method must return an iterator, which is used in iteration protocols such as the for loop. You create an iterator from the list .points using the built-in iter() function. Although adding .__iter__() is not necessary to ensure a ShapePoints object is a sequence, most iterables implement this special method.
You can visualize the shape with the help of the turtle module, which is the simplest way to display graphics using Python’s standard library. Now you can create a new script to run this code:
draw_shape.py
import turtle
from shape import ShapePoints
triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
# Draw the shape using turtle graphics
turtle.penup()
# Move to the first point
turtle.setposition(triangle[0])
turtle.pendown()
# Draw lines to the other points
for point in triangle[1:]:
turtle.setposition(point)
turtle.done()
The output shows the shape defined by the points in the ShapePoints object:
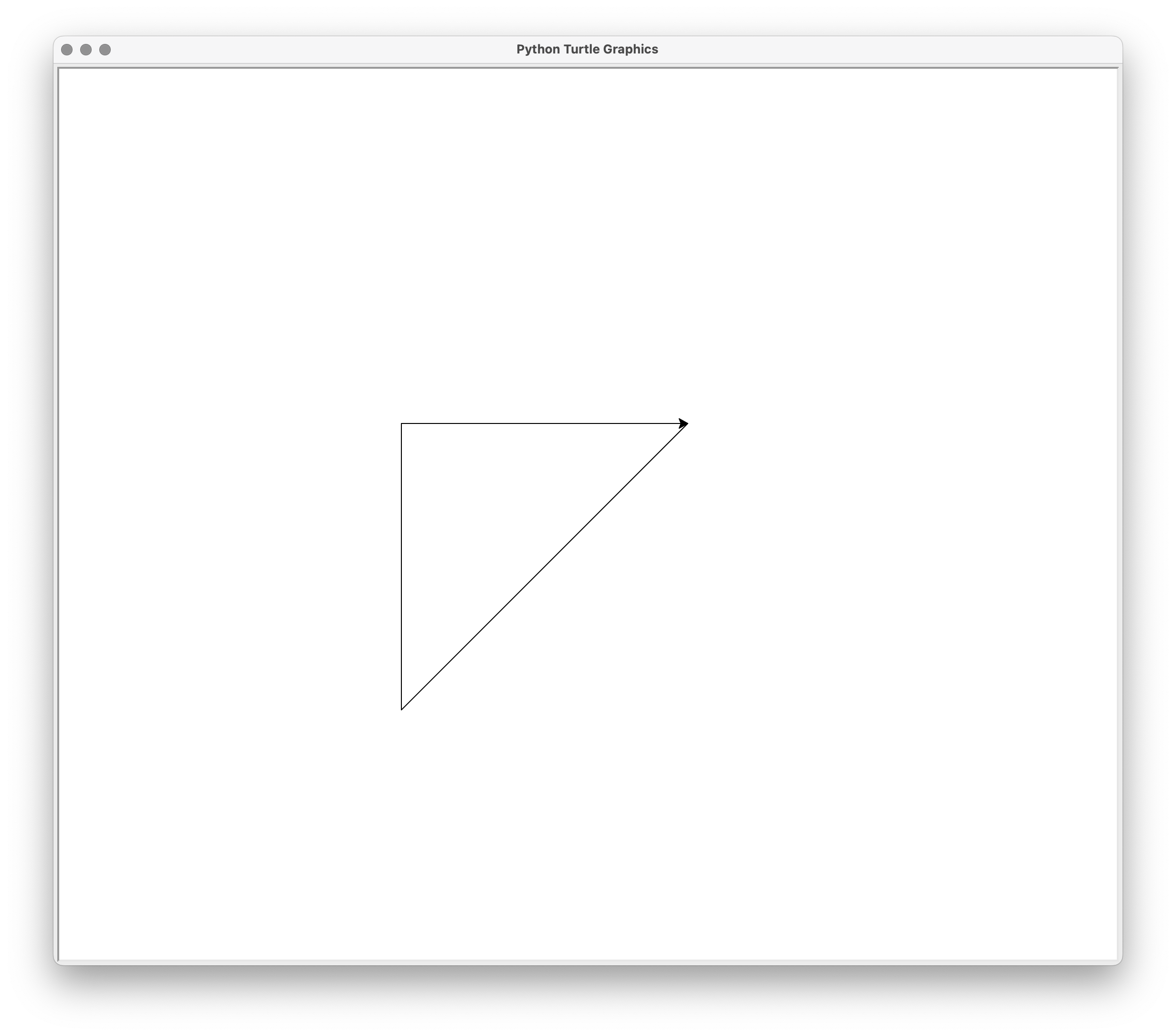
You’ll continue to work with the ShapePoints class in the following section as you learn about another way to create user-defined sequences.
Using the Abstract Base Class collections.abc.Sequence
You’ve learned about the minimum requirements for an object to be a sequence. A sequence must be iterable, have a length, and be indexable. Many sequences can also be sliced but this is not a feature that’s universal to all sequences. There are other features that are common to many sequences, even though they’re not required.
The abstract base class collections.abc.Sequence provides a template that defines the interface for most sequences. This abstract base class goes further than the minimum requirements. You can use this abstract base class to confirm whether a data type is a sequence:
>>> from collections.abc import Sequence
>>> isinstance([2, 4, 6], Sequence)
True
>>> isinstance((2, 4, 6), Sequence)
True
>>> isinstance({2, 4, 6}, Sequence)
False
>>> isinstance({"A Key": "A Value"}, Sequence)
False
You confirm that lists and tuples are sequences, but sets and dictionaries aren’t. However, the Sequence abstract base class sets a higher bar for defining sequences than the basic definition you learned earlier. You can try to check whether ShapePoints is a sequence:
>>> from shape import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> isinstance(triangle, Sequence)
False
Earlier in this tutorial, you added special methods to ShapePoints to ensure it meets the requirements for a sequence. However, it doesn’t meet the higher standards set by the Sequence abstract base class. You’ll explore these additional features shortly.
There are two apparent definitions of a sequence, which may lead to confusion. In practice, this is rarely an issue, and most sequences meet the higher standards set by the abstract base class Sequence.
You can redefine the ShapePoints class in a new file called shape_abc.py. In this version, the class inherits from the Sequence abstract base class. Start by defining the class’s __init__() special method as in the earlier version:
shape_abc.py
from collections.abc import Sequence
class ShapePoints(Sequence):
def __init__(self, points):
self.points = list(points)
if points and self.points[0] != self.points[-1]:
self.points.append(self.points[0])
The new class inherits from the abstract base class Sequence. Try to create an instance of this class in the REPL. Note that you’re now importing from the new module shape_abc.py:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
Traceback (most recent call last):
...
TypeError: Can't instantiate abstract class ShapePoints without an
implementation for abstract methods '__getitem__', '__len__'
When you try to create an instance of ShapePoints, you get an error. You can’t have a sequence without the .__getitem__() and .__len__() methods. You need to define these in a way that suits your class before you can proceed. You can use the same definitions you used in the earlier version, and you can also add .__repr__() and .__iter__():
shape_abc.py
from collections.abc import Sequence
class ShapePoints(Sequence):
def __init__(self, points):
self.points = list(points)
if points and self.points[0] != self.points[-1]:
self.points.append(self.points[0])
def __repr__(self):
return f"ShapePoints({self.points})"
def __getitem__(self, index):
return self.points[index]
def __len__(self):
if self.points:
return len(self.points) - 1
return 0
def __iter__(self):
return iter(self.points)
The ShapePoints object now meets the stricter standards set by the Sequence abstract base class. You can confirm this in a new REPL session:
>>> from collections.abc import Sequence
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> isinstance(triangle, Sequence)
True
What does this mean? What extra features does ShapePoints have now that it’s a subclass of the collections.abc.Sequence abstract base class? You’ll explore the answers to these questions in the following sections.
The .index() and .count() Methods in Sequences
Objects of different data types have different methods. However, some data types also share methods with similar names. For example, lists, strings, and tuples all have a .index() method to find the position of an item and a .count() method to find how often an item occurs in the data structure. In fact, these two methods are the only methods tuples have that aren’t special methods.
Most sequences have access to .index() and .count() methods. These methods are part of the interface provided by collections.abc.Sequence. You can confirm this by calling these methods on the ShapePoints instance you created in the previous section:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle
ShapePoints([(100, 100), (-200, 100), (-200, -200), (100, 100)])
>>> triangle.index((100, 100))
0
>>> triangle.count((100, 100))
2
The object triangle has access to these methods even though you don’t define them when you create the ShapePoints class. The first output shows the index of the item (100, 100), which is 0. The .index() method returns the index of its argument’s first occurrence if there’s more than one. This method relies on .__getitem__() to fetch each item until the required value is found, or it raises a ValueError if the value is not present.
The first element is repeated at the end of the sequence since shapes are closed. Therefore, .count() returns 2 as there are two occurrences of (100, 100). This method relies on .__iter__() to iterate through the whole sequence and count the occurrences of the value passed as an argument. If .__iter__() is not defined, then .__getitem__() is used instead.
However, you don’t want to count the first point in the shape twice, so you can override the .count() method:
from collections.abc import Sequence
class ShapePoints(Sequence):
# ...
def count(self, value):
return self.points[:-1].count(value)
You create your own .count() method rather than using the one inherited from the Sequence abstract base class. You exclude the last point in the shape by counting the number of occurrences of the required value in .points[:-1]. The slice includes all the points except the one with index -1, which is the last element. You can refresh the REPL to make sure this works:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle.count((100, 100))
1
The .index() and .count() methods are included when you create a sequence by inheriting from the abstract base class. However, you can also override the default methods by defining your own versions.
The Container and Reversible Features for Sequences
Sequences usually also have two more characteristics:
- They are containers.
- They are reversible.
In this section of the tutorial, you’ll explore these two data types characteristics and how to ensure your user-defined sequences are also containers and reversible.
Many data structures are also containers, which means that Python can determine whether an element is a member of the data structure. A common way to find out whether a data structure contains an element is to use the in keyword:
>>> countries = ["USA", "Canada", "UK", "Norway", "Malta", "India"]
>>> "Canada" in countries
True
>>> "Spain" in countries
False
However, this is not sufficient to confirm that a data structure is a container. For example, if you use the in keyword on an iterator, you may not get the results you expect:
>>> countries_iterator = iter(countries)
>>> "Canada" in countries_iterator
True
>>> "Canada" in countries_iterator
False
You create an iterator from the list countries. Python returns True the first time you check whether Canada is one of the countries included in the data structure. But an iterator generates items when they’re required and doesn’t store them. So, the second time you check for membership, Python returns False. That being the case, iterators are not containers.
You can control the definition of membership of an element using the .__contains__() special method. This is one of the methods that’s included in the Sequence abstract base class. You can confirm that the class ShapePoints you created, which inherits from Sequence, has this special method:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle.__contains__((100, 100))
True
>>> (100, 100) in triangle
True
You call the special method .__contains__() directly on triangle to confirm this special method exists even though you didn’t define it in the class. It’s inherited from the Sequence abstract base class.
Keep in mind that it’s best to avoid calling the special method directly. Special methods are intended to be called behind the scenes. For example, the .__contains__() special method is called when you use the in operator if the special method is available.
If you have specific requirements for what membership means in a user-defined class, you can override this method:
shape_abc.py
from collections.abc import Sequence
class ShapePoints(Sequence):
# ...
def __contains__(self, item):
print("Checking if item is in ShapePoints")
return item in self.points
You define the special method in the class definition. In this example, you add a call to print() to highlight when the program calls this method. When you repeat the statements from the previous REPL session, you’ll also see this text displayed:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle.__contains__((100, 100))
Checking if item is in ShapePoints
True
>>> (100, 100) in triangle
Checking if item is in ShapePoints
True
The extra sentence is printed when you call .__contains__() directly and when you use the in operator, which confirms that both expressions are equivalent.
Another special method that’s included in the abstract base class Sequence is .__reversed__(). This method defines how a sequence can be reversed, and it’s called by functions such as the built-in reversed().
Note: The .__contains__() and .__reversed__() special methods aren’t necessary for an object to be a container and reversible. The .__getitem__() special method does a lot of heavy lifting, and Python will fall back onto this method to determine whether an item is a member of a data structure or to reverse the sequence.
You can confirm this with the earlier version of ShapePoints you created, which doesn’t inherit from Sequence and, therefore, doesn’t include these special methods.
However, these methods make the intention clearer and allow you to customize your class’s behavior.
All sequences are containers and are reversible, and they include the .__contains__() and .__reversed__() special methods if they follow the collections.abc.Sequence requirements.
Creating Immutable and Mutable Sequences
You defined a class called ShapePoints, which inherits from the abstract base class collections.abc.Sequence. Next, you try to modify one of the points in an instance of ShapePoints:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> triangle[1]
(-200, 100)
>>> triangle[1] = (-250, 150)
Traceback (most recent call last):
...
TypeError: 'ShapePoints' object does not support item assignment
The expression triangle[1] returns the tuple representing the second point in the shape. This behavior is defined by the .__getitem__() special method. However, when you try to assign a new tuple to the second position of your sequence, the program raises an exception.
The sequence you create is immutable. Immutable built-in sequences include tuples and strings. Therefore, the sequence you create is similar to these built-in sequences since you can’t make changes to an object once it’s created.
None of the methods and special methods available to the class make changes to the data stored within the sequence. All methods, whether you write them or they’re inherited from Sequence, return values without modifying the state of the object.
Note: Special methods such as .__init__() and .__new__() do make changes to the object. But these are only called when you create a new instance since their purpose is to create a new object and initialize it.
Still, it’s possible to have mutable sequences. The built-in list is the most common example of a mutable sequence. You’ll learn how to create a user-defined class for a mutable sequence in the following section.
Requirements for Defining a User-Defined Mutable Sequence
You can make your custom sequence mutable by inheriting from a different abstract base class called collections.abc.MutableSequence :
shape_abc.py
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
# ...
You import MutableSequence instead of Sequence in shape_abc.py. The class ShapePoints now inherits from MutableSequence. However, you’ll get an error when you try to create an instance of this class in a new REPL session:
>>> from shape_abc import ShapePoints
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
Traceback (most recent call last):
...
TypeError: Can't instantiate abstract class ShapePoints without an
implementation for abstract methods '__delitem__', '__setitem__', 'insert'
You can’t have a mutable sequence without defining three new methods:
.__delitem__(): This special method defines what should happen when an item is deleted from the sequence, such as when you use thedelkeyword..__setitem__(): This special method defines the object’s behavior when you assign a value to a position in the sequence, such as when you reassign a new value to replace an existing one..insert(): This method defines the behavior when you insert a new value in an existing sequence.
The data in a ShapePoints object is stored in a list within the data attribute .points. A list is a sequence, so you can use the list’s mutable properties:
shape_abc.py
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
# ...
def __delitem__(self, index):
del self.points[index]
def __setitem__(self, index, value):
self.points[index] = value
def insert(self, index, value):
self.points.insert(index, value)
You define deleting an item from the sequence as the same as deleting the corresponding item from the list .points. The operations to set and insert an item also use the equivalent operations on the list .points. Adding these methods is sufficient to make the sequence mutable.
You can also improve the logic in these methods to account for the special requirements for a closed shape, where the first and last elements are the same. You can account for this requirement in the definitions of the new methods. To start, update .__delitem__():
shape_abc.py
1from collections.abc import MutableSequence
2
3class ShapePoints(MutableSequence):
4 # ...
5
6 def __delitem__(self, index):
7 if index in (0, len(self.points) - 1, -1):
8 del self.points[0]
9 self.points[-1] = self.points[0]
10 else:
11 del self.points[index]
12
13 # ...
Whenever you delete the first or last elements, which represent the same point, you need to delete the first element and replace the last element so it’s equal to the sequence’s new first element. Ideally, you should also ensure that the sequence isn’t empty before deleting an element, but you’ll change how you handle such sequences shortly.
You implement this functionality in a few steps:
-
In line 7, you check whether the
indexthat you pass to.__delitem__()is either0,-1, or the last index ofself.points. If it is, then you’re dealing with the point that’s duplicated to represent a closed shape. -
If the expression in line 7 evaluates to
True, then you delete the first point of your custom sequence in line 8. This removes the duplicate point at the beginning of your sequence. -
Next, in line 8, you remove the duplicate point from the end of the sequence by replacing it with the value of the new first point. That way, you’ve successfully removed both instances of the duplicate point.
If you want to delete any other point of the sequence, then you delete it without any additional actions in the else block.
You can confirm this works in a new REPL session. You add a few more points to the shape to make it easier to test the changes you made:
>>> from shape_abc import ShapePoints
>>> polygon = ShapePoints(
... [
... (20, 20),
... (-200, 0),
... (80, 80),
... (50, 50),
... (0, 0),
... ]
... )
>>> polygon
ShapePoints([(20, 20), (-200, 0), (80, 80), (50, 50), (0, 0), (20, 20)])
>>> del polygon[1]
>>> polygon
ShapePoints([(20, 20), (80, 80), (50, 50), (0, 0), (20, 20)])
>>> del polygon[0]
>>> polygon
ShapePoints([(80, 80), (50, 50), (0, 0), (80, 80)])
>>> del polygon[-1]
>>> polygon
ShapePoints([(50, 50), (0, 0), (50, 50)])
You start with a shape with five points. Since shapes are closed, the object actually has six elements as the first point is duplicated at the end of the sequence. Next, you delete an element that isn’t at either end of the sequence with the statement del polygon[1]. Only the second point is deleted. When you remove the first or last element, both ends are updated to reflect the new shape.
Note that in the last step, the shape only has two points, since the last element is always equal to the first. This shape represents a line, which is not a closed shape. A ShapePoints object with only one point represents that point, which is also not a closed shape. If you prefer, you could define ShapePoints to be valid only for three or more points to ensure you have a closed shape:
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
MIN_POINTS = 3
def __init__(self, points):
self.points = list(points)
if len(self.points) < self.MIN_POINTS:
raise ValueError(
f"Shape must have at least {self.MIN_POINTS} points"
)
if self.points[0] != self.points[-1]:
self.points.append(self.points[0])
# ...
def __delitem__(self, index):
if len(self) < self.MIN_POINTS + 1:
raise ValueError(
f"Shape must have at least {self.MIN_POINTS} points"
)
if index in (0, len(self.points) - 1, -1):
del self.points[0]
self.points[-1] = self.points[0]
else:
del self.points[index]
# ...
You add a class attribute .MIN_POINTS to define the minimum number of points an object can have. Then you update both .__init__() and .__delitem__() to raise an error when there’s an invalid number of points.
When you initialize the object, you confirm that the iterable you pass to create the instance contains at least three points since .MIN_POINTS is 3 in this example. When you call .__delitem__(), you check that there are at least four points before deleting one.
You can confirm these changes in a new REPL session:
>>> from shape_abc import ShapePoints
>>> line = ShapePoints([(0, 0), (50, 80)])
Traceback (most recent call last):
...
raise ValueError(
ValueError: Shape must have at least 3 points
>>> triangle = ShapePoints([(100, 100), (-200, 100), (-200, -200)])
>>> del triangle[0]
Traceback (most recent call last):
...
raise ValueError(
ValueError: Shape must have at least 3 points
You get a ValueError when you try to create a line with only two points. You also get the same exception when you try to delete a point from a triangle since a ShapePoints object can’t have fewer than three points. Note that the adjustment you made earlier to .__len__() to ensure it works for empty sequences isn’t needed now since a ShapePoints object can no longer be empty.
You also need to account for the special requirements of a closed shape when you modify a point. Therefore, you need to update .__setitem__() similarly to how you modified .__delitem__():
shape_abc.py
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
# ...
def __setitem__(self, index, value):
if index in (0, len(self.points) - 1, -1):
self.points[0] = value
self.points[-1] = value
else:
self.points[index] = value
# ...
You update both the first and last elements of the sequence when the user sets either the first or the last element. For any other element, you only set the value required. The following examples in a new REPL session confirm that .__setitem__() works the way you expect:
>>> from shape_abc import ShapePoints
>>> polygon = ShapePoints(
... [
... (20, 20),
... (-200, 0),
... (80, 80),
... (50, 50),
... (0, 0),
... ]
... )
>>> polygon
ShapePoints([(20, 20), (-200, 0), (80, 80), (50, 50), (0, 0), (20, 20)])
>>> polygon[1] = (99, 99)
>>> polygon
ShapePoints([(20, 20), (99, 99), (80, 80), (50, 50), (0, 0), (20, 20)])
>>> polygon[0] = (44, 44)
>>> polygon
ShapePoints([(44, 44), (99, 99), (80, 80), (50, 50), (0, 0), (44, 44)])
>>> polygon[-1] = (-22, -22)
>>> polygon
ShapePoints([(-22, -22), (99, 99), (80, 80), (50, 50), (0, 0), (-22, -22)])
Only the second element is updated when you assign a new value to polygon[1]. However, you modify both the first and last values when you update polygon[0]. You also modify both the first and last values when you change the last element in the ShapePoints object.
Finally, you update the .insert() method:
shape_abc.py
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
# ...
def insert(self, index, value):
if index in (0, len(self.points) - 1, -1):
self.points.insert(0, value)
self.points[-1] = value
else:
self.points.insert(index, value)
Any value inserted in the first or last position updates both values. If the value updated is not the first or last element, you can use the standard insertion at the required position. You can confirm that the changes to .insert() achieve the outcome required. In this example, you start with a shape with fewer points in a new REPL session:
>>> from shape_abc import ShapePoints
>>> polygon = ShapePoints(
... [
... (80, 80),
... (50, 50),
... (0, 0),
... ]
... )
>>> polygon
ShapePoints([(80, 80), (50, 50), (0, 0), (80, 80)])
>>> polygon.insert(1, (30, 30))
>>> polygon
ShapePoints([(80, 80), (30, 30), (50, 50), (0, 0), (80, 80)])
>>> polygon.insert(0, (40, 40))
>>> polygon
ShapePoints([(40, 40), (80, 80), (30, 30), (50, 50), (0, 0), (40, 40)])
>>> polygon.insert(-1, (5, 5))
>>> polygon
ShapePoints(
[(5, 5), (40, 40), (80, 80), (30, 30), (50, 50), (0, 0), (5, 5)]
)
Your code treats insertion at the first and last positions differently to ensure the new shape remains closed.
Additional Methods Associated With Mutable Sequences
When a class inherits from collections.abc.MutableSequence, it also inherits several other methods. You’ll recognize some or all of these methods from your experience with using lists:
.append(): Add a new item to the end of the sequence..clear(): Remove all items from the sequence..reverse(): Reverse the items of the sequence in place, changing the existing object rather than returning a new one..extend(): Add several additional items to the end of the sequence by passing another sequence as an argument..pop(): Remove an item based on its index. This method returns the item that’s removed from the sequence..remove(): Remove an item based on its value. This method removes the first occurrence of the value in the sequence..__iadd__(): This special method defines the behavior for the augmented addition operator+=, which for mutable sequences becomes an in-place operator.
All of these methods are included by default when you inherit from MutableSequence. However, you may need to override their behavior if your sequence has certain non-standard requirements, such as the ShapePoints sequence. You can test these methods on the current version of ShapePoints:
>>> from shape_abc import ShapePoints
>>> polygon = ShapePoints(
... [
... (80, 80),
... (50, 50),
... (0, 0),
... ]
... )
>>> polygon
ShapePoints([(80, 80), (50, 50), (0, 0), (80, 80)])
>>> polygon.append((75, 25))
>>> polygon
ShapePoints([(75, 25), (80, 80), (50, 50), (0, 0), (75, 25)])
>>> polygon.extend([(10, 0), (30, 30)])
>>> polygon
ShapePoints(
[(30, 30), (10, 0), (75, 25), (80, 80), (50, 50), (0, 0), (30, 30)]
)
>>> polygon.remove((30, 30))
>>> polygon
ShapePoints([(10, 0), (75, 25), (80, 80), (50, 50), (0, 0), (10, 0)])
>>> polygon += [(90, 40), (10, 50)]
>>> polygon
ShapePoints(
[(10, 50), (90, 40), (10, 0), (75, 25), (80, 80), (50, 50), (0, 0), (10, 50)]
)
You start with a shape with two points. You call .append() and .extend() to add points to the shape. Next, you remove a point, use the augmented addition operator += to extend the sequence again, and finally reverse the sequence.
The code doesn’t raise any exceptions since all the methods exist. However, not all these methods behave the way you might expect them to. Currently, .append() adds a point at the beginning and the end of the sequence. For this implementation of ShapePoints, that’s not what you want .append() to do.
The problem occurs because you defined the class with special behavior when new points are added at the end. So, when you update the last element using the default .append() method inherited from the abstract base class, the ShapePoints class also updates the first element.
You can see similar odd behavior with .extend() and the += operator since these operations rely on .append(). The new points are added to the beginning and the end of the shape.
When the default methods you inherit from the abstract base class aren’t suitable, you can override them. However, it may not be necessary to define all the methods. With mutable sequences, .append() is often a method you may wish to update first when the defaults aren’t sufficient:
shape_abc.py
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
# ...
def append(self, value):
self.points.append(self.points[0])
self.points[-2] = value
You redefine .append() to add a new point before the final element since the final element mirrors the first one. Therefore, you call .append() on the list stored in the data attribute .points and add the first element of the sequence. Now, you can update the element with index -2, which is no longer the last element of the sequence, but it’s the last point in the shape.
You can verify what happens to the same operations you tried earlier in a new REPL session:
>>> from shape_abc import ShapePoints
>>> polygon = ShapePoints(
... [
... (80, 80),
... (50, 50),
... (0, 0),
... ]
... )
>>> polygon
ShapePoints([(80, 80), (50, 50), (0, 0), (80, 80)])
>>> polygon.append((75, 25))
>>> polygon
ShapePoints([(80, 80), (50, 50), (0, 0), (75, 25), (80, 80)])
>>> polygon.extend([(10, 0), (30, 30)])
>>> polygon
ShapePoints(
[(80, 80), (50, 50), (0, 0), (75, 25), (10, 0), (30, 30), (80, 80)]
)
>>> polygon.remove((30, 30))
>>> polygon
ShapePoints([(80, 80), (50, 50), (0, 0), (75, 25), (10, 0), (80, 80)])
>>> polygon += [(90, 40), (10, 50)]
>>> polygon
ShapePoints(
[(80, 80), (50, 50), (0, 0), (75, 25), (10, 0), (90, 40), (10, 50), (80, 80)]
)
When you append a new point to a ShapePoints sequence, the additional point is added to the shape, but the final element remains matched to the first element. This correct behavior now applies to .extend() and the += operator. So, overriding the .append() method also deals with these operations since they call .append() behind the scenes. All operations now work as intended.
The abstract base classes Sequence and MutableSequence provide you with the methods you need to create custom sequences. When you define a class that inherits from Sequence, you need to define at least two special methods:
.__getitem__().__len__()
If you need a mutable sequence and your class inherits from MutableSequence, you’ll also need at least three more methods in addition to the two special methods listed above:
.__setitem__().__delitem__().insert()
All sequences will also have .index() and .count() available out of the box, and mutable sequences have more methods you can use or override if you require special behavior.
Here’s the final version of the ShapePoints class definition you wrote in this tutorial:
shape_abc.py
from collections.abc import MutableSequence
class ShapePoints(MutableSequence):
MIN_POINTS = 3
def __init__(self, points):
self.points = list(points)
if len(self.points) < self.MIN_POINTS:
raise ValueError(
f"Shape must have at least {self.MIN_POINTS} points"
)
if self.points[0] != self.points[-1]:
self.points.append(self.points[0])
def __repr__(self):
return f"ShapePoints({self.points})"
def __getitem__(self, index):
return self.points[index]
def __len__(self):
return len(self.points) - 1
def __iter__(self):
return iter(self.points)
def __contains__(self, item):
print("Checking if item is in ShapePoints")
return item in self.points
def __delitem__(self, index):
if len(self) < self.MIN_POINTS + 1:
raise ValueError(
f"Shape must have at least {self.MIN_POINTS} points"
)
if index in (0, len(self.points) - 1, -1):
del self.points[0]
self.points[-1] = self.points[0]
else:
del self.points[index]
def __setitem__(self, index, value):
if index in (0, len(self.points) - 1, -1):
self.points[0] = value
self.points[-1] = value
else:
self.points[index] = value
def insert(self, index, value):
if index in (0, len(self.points) - 1, -1):
self.points.insert(0, value)
self.points[-1] = value
else:
self.points.insert(index, value)
def count(self, value):
return self.points[:-1].count(value)
def append(self, value):
self.points.append(self.points[0])
self.points[-2] = value
Conclusion
Different data types often share common traits, and it’s useful to categorize them based on their shared features. Sequences are data types that contain ordered items which can be accessed using an integer index. In addition to the basic requirements that make an object a sequence, there are other features that are present in many sequences.
In this tutorial, you learned about:
- Basic characteristics of a sequence
- Operations that are common to most sequences
- Special methods associated with sequences
- Abstract base classes
SequenceandMutableSequence - User-defined mutable and immutable sequences and how to create them
You’re now better equipped to use all the data types that fall under the sequences category, and you know how to deal with functions requiring arguments that are sequences. You’re also ready to craft the ideal custom classes whenever you need to create your own mutable or immutable sequences.
Get Your Code: Click here to download the free sample code that you’ll use to learn about Python sequences in this comprehensive guide.
Take the Quiz: Test your knowledge with our interactive “Python Sequences: A Comprehensive Guide” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python Sequences: A Comprehensive GuideIn this quiz, you'll test your understanding of sequences in Python. You'll revisit the basic characteristics of a sequence, operations common to most sequences, special methods associated with sequences, and how to create user-defined mutable and immutable sequences.






