
With the upcoming release of Python 3.12 this fall and Python 3.13 following a year later, you might have heard about how Python subinterpreters are changing. The upcoming changes will first give extension module developers better control of the GIL and parallelism, potentially speeding up your programs.
The following release may take this even further and allow you to use subinterpreters from Python directly, making it easier for you to incorporate them into your programs!
In this tutorial, you’ll:
- Get a high-level view of what Python subinterpreters are
- Learn how changes to CPython’s global state in Python 3.12 may change things for you
- Get a glimpse of what changes might be coming for subinterpreters in Python 3.13
To get the most out of this tutorial, you should be familiar with the basics of Python, as well as with the global interpreter lock (GIL) and concurrency. You’ll encounter some C code, but only a little.
You’ll find many other new features, improvements, and optimizations in Python 3.12. The most relevant ones include the following:
- Ever better error messages
- Support for the Linux
perfprofiler - More powerful f-strings
- Improved static typing features
Go ahead and check out what’s new in the changelog for more details on these and other features or listen to our comprehensive podcast episode. It’s definitely worth your time to explore what’s coming!
Free Bonus: Click here to download your sample code for a sneak peek at Python 3.12, coming in October 2023.
What Are Python Subinterpreters?
Before you start thinking about subinterpreters, recall that an interpreter is a program that executes a script directly in a high-level language instead of translating it to machine code. In the case of most Python users, CPython is the interpreter you’re running. A subinterpreter is a copy of the full CPython interpreter that can run independently from the main interpreter that started alongside your program.
Note: The terms interpreter and subinterpreter get mixed together fairly commonly. For the purposes of this tutorial, you can view the main interpreter as the one that runs when your program starts. All other interpreters that start after that point are considered subinterpreters. Other than a few minor details, subinterpreters are the same type of object as the main interpreter.
Most of the state of the subinterpreter is separate from the main interpreter. This includes elements like the global scope name table and the modules that get imported. However, this doesn’t include some of the items that the operating system provides to the process, like file handles and memory.
This is different from threading or other forms of concurrency in that threads can share the same context and global state while allowing a separate flow of execution. For example, if you start a new thread, then it still has the same global scope name table.
A subinterpreter, however, can be described as a collection of cooperating threads that have some shared state. These threads will have the same set of imports, independent of other subinterpreters. Spawning new threads in a subinterpreter adds new threads to this collection, which won’t be visible from other interpreters.
Some of the upcoming changes that you’ll see will also allow subinterpreters to improve parallelism in Python programs.
Subinterpreters have been a part of the Python language since version 1.5, but they’ve only been available as part of the C-API, not from Python. But there are large changes coming that will make them more useful and interesting for everyday Python users.
What’s Changing in Python 3.12 (PEP 684)?
Now that you know what a Python subinterpreter is, you’ll take a look at what’s changing in the upcoming releases of CPython.
Most of the subinterpreter changes are described in two proposals, PEP 684 and PEP 554. Only PEP 684 will make it into the 3.12 release. PEP 554 is scheduled for the 3.13 release but hasn’t been officially approved yet.
Changes to the Global State and the GIL
The main focus of PEP 684 is refactoring the internals of the CPython source code so that each subinterpreter can have its own global interpreter lock (GIL). The GIL is a lock, or mutex, which allows only one thread to have control of the Python interpreter. Until this PEP, there was a single GIL for all subinterpreters, which meant that no matter how many subinterpreters you created, only one could run at a single time.
Moving the GIL so that each subinterpreter has a separate lock is a great idea. So, why hasn’t it been done already? The issue is that the GIL is preventing multiple threads from accessing some of the global state of CPython simultaneously, so it’s protecting your program from bugs that race conditions could cause.
The core developers needed to move much of the previously global state into per-interpreter storage, meaning each interpreter has its own independent version:
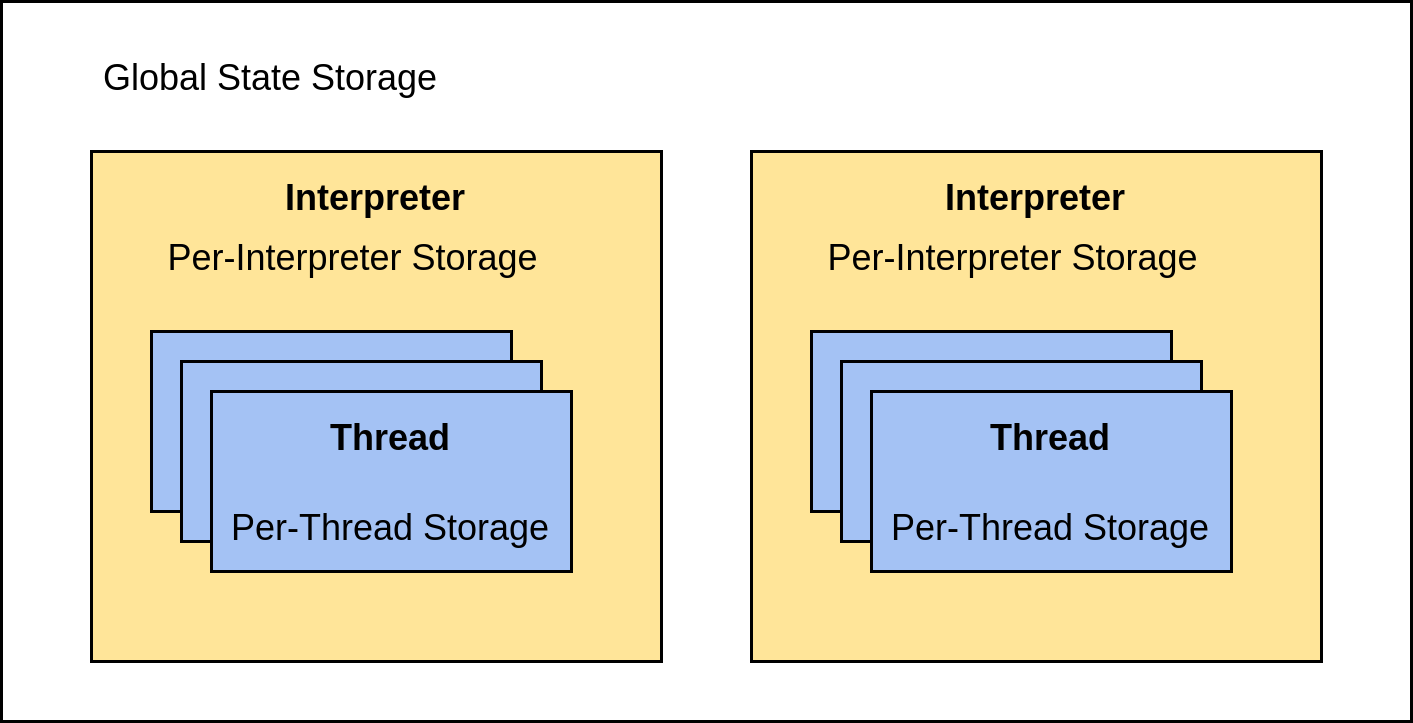
There’s still some global state in CPython, but each interpreter has its own set of state, as well as its own collection of threads. Each of these threads, in turn, has a per-thread storage section.
Other protection mechanisms are necessary for anything that can’t go into per-interpreter state and has to remain in the global state.
To implement those protections, the core developers modified several aspects of the CPython source code. In previous versions of CPython, fields like the object allocator, obmalloc, were part of the global state. This, along with other variables holding state, were moved to the PyInterpreterState struct, isolating them to each interpreter.
While there are other examples, the obmalloc move is an interesting one. The object allocator—you guessed it—allocates new objects in memory. Since everything in Python is an object, you use it quite frequently. With the object allocator as a shared resource, objects could theoretically leak between interpreters, causing potential problems.
As you learned above, the PyInterpreterState struct now contains all per-interpreter values. This struct is really just an alias for the _is struct in the CPython source code. The is here stands for interpreter state.
If you browse this structure, then you’ll see members like imports, a linked list of threads, a dict of the builtins module, and the initial state of this interpreter. Each of these items is stored independently by every interpreter and is fundamental to how CPython manages threads and intepreters.
The effort to reduce this global state has been going on for several years, and this PEP relies on that effort’s being largely complete. There’s more information on bugs and caveats related to subinterpreters in the C-API documentation, which describes some of the difficulties here.
PEP 684 layers on top of this work to move global state to PyInterpreterState. The big change for this PEP was adding the _gil_runtime_state member to this structure:
/* The per-interpreter GIL, which might not be used. */
struct _gil_runtime_state _gil;
The comment indicates that this field is optional, so you can still run CPython in the standard, single-GIL way.
But modules that chose to implement some changes now have the option to create subinterpreters that have independent GILs. Since the GIL prevents threads from running simultaneously, the modules that take this step will be able to run threads at the same time on different cores, provided they’re in separate interpreters.
There’s also a good deal of discussion about trying to entirely remove the GIL from CPython. While there are currently proposals and discussions, none of these have been fully accepted or scheduled.
Changes to Extension Modules
Having true parallelism in Python by allowing subinterpreters to have independent GILs sounds like a great idea, but there are several complications that arise from this change. One of the biggest ones is that there are many, many packages built using the C-API in other languages—such as C, Rust, and Fortran—that use global state internally.
Up until PEP 684, they relied on the GIL to prevent multiple subinterpreters from accessing this state in separate threads.
With the GIL moving to be a per-interpreter state, this guaranteed thread safety is removed. To prevent either a large number of bugs in existing extension modules or a lack of adoption of Python 3.12, methods were added so that when you want to import a module, Python can first determine whether it’s ready for this new feature.
Note: If a subinterpreter with a per-interpreter GIL attempts to import a module that doesn’t support this feature, then Python will raise an ImportError.
Extension modules that use the multi-stage initialization process defined in PEP 489 are generally able to run in multiple subinterpreters. Before you dive into that, here’s what the multi-stage initialization process looks like first.
Multi-phase initialization was added to allow extension modules to control the initialization process with much more granularity than the single-phase method, where CPython basically called a single function and was done. PEP 489 changed a previously unused field in the PyModuleDef structure to hold a list of PyModuleDef_Slot structures:
struct PyModuleDef_Slot {
int slot;
void *value;
};
Each of these slots holds an integer label indicating which slot it’s filling and a value for that slot. PEP 489 defines two of these slots:
Py_mod_create, which gets called during module creationPy_mod_exec, which is called before the module runs
Note: Slots is a term that this portion of the Python code uses to describe a key-value pair. Each slot has a label, which is called slot in the structure above, and a value, called value, appropriately enough. The extension writers create an array, which is like a Python List in C, of these slots to pass extra information about the extension to Python.
Even though math only uses one of the two slots defined, this standard library module demonstrates the new syntax:
1static int
2math_exec(PyObject *module)
3{
4 // ...function body skipped...
5}
6
7static PyModuleDef_Slot math_slots[] = {
8 {Py_mod_exec, math_exec},
9 {0, NULL}
10};
11
12static struct PyModuleDef mathmodule = {
13 PyModuleDef_HEAD_INIT,
14 .m_name = "math",
15 .m_doc = module_doc,
16 .m_size = sizeof(math_module_state),
17 .m_methods = math_methods,
18 .m_slots = math_slots,
19 .m_clear = math_clear,
20 .m_free = math_free,
21};
22
23PyMODINIT_FUNC
24PyInit_math(void)
25{
26 return PyModuleDef_Init(&mathmodule);
27}
If you start at the bottom, then you see the PyInit_math() function on lines 24 to 27, which is called when you import the module. This returns an initialized PyModuleDef object. Above this function, starting in line 12, is the definition of mathmodule, which is the PyModuleDef object for this module.
The .m_slots member of this structure, which you can find on line 18, is the addition that was made for PEP 489. It adds a list of slots, which are optional entry points that CPython will call if provided. Like you learned above, PEP 489 defined two of these slots, Py_mod_create which is called during the object creation phase, and Py_mod_exec which is called when you load the module.
This setup allows module maintainers to initialize a module in multiple steps, allowing for more granularity for when to run what code. In the example above, the math module calls math_exec() only when Python loads the math module, and not before.
Now that you know how multi-stage initialization works, you can focus again on the changes that PEP 684 has introduced.
The code that you’ve seen so far was from before the implementation of PEP 684. That PEP adds a new slot to the PyModuleDef_Slot array:
1static PyModuleDef_Slot math_slots[] = {
2 {Py_mod_exec, math_exec},
3 {Py_mod_multiple_interpreters, Py_MOD_PER_INTERPRETER_GIL_SUPPORTED},
4 {0, NULL}
5};
Line 3 shows the added slot, which tells CPython that this module supports a per-interpreter GIL.
The second slot, Py_mod_multiple_interpreters, can currently have one of three values:
Py_MOD_MULTIPLE_INTERPRETERS_NOT_SUPPORTED, which has the value 0Py_MOD_MULTIPLE_INTERPRETERS_SUPPORTED, which has the value 1Py_MOD_PER_INTERPRETER_GIL_SUPPORTED, which has the value 2
In the code block above, you can see that the math module will fully support the per-interpreter GIL changes.
Note: A C define sets the value for these three options. This is a way to do a text substitution. Everywhere in the C module where, for example, Py_MOD_PER_INTERPRETER_GIL_SUPPORTED appears, the compiler uses ((void *)2) which, for your purposes, is 2. The void * portion is some special syntax to make sure that C creates the value correctly.
These changes are what a module needs to tell CPython that it can run in this mode. It’s up to the extension module writer to ensure that the module really adheres to the restrictions, however.
This can be trickier than it would first appear. Some functions in the C standard library, strtok() for example, have internal state, which means that they’re not thread-safe.
When running in single-GIL Python versions, the GIL protects against multiple threads’ accessing this memory at the same time. Switching to a per-interpreter GIL system moves this responsibility to the module writer. You can either use a mutex to serialize access or find a thread-safe version of the function in question.
The slot-based system of indicating a module’s readiness for a per-interpreter GIL means that PEP 684 is an opt-in feature. In other words, extension modules will need to make at least one change to take advantage of this feature. By default, they’ll get the single GIL behavior.
Adding this flag means that existing modules will still work and will still show the same behavior that you’re used to, but it’ll allow new and existing modules to advance to take advantage of a per-interpreter GIL. It also means that it’ll likely take a while for many modules to switch to this new model, though several of the standard library models will be updated to do so in the 3.12 release.
Why This Matters
Moving the GIL from being a single lock to a per-interpreter lock is a lot of work, both for the Python core developers and the maintainers of external modules. Why do all this work?
The single-point GIL in Python is a feature that adds some simplicity to the lives of developers, but it comes at a cost. Moving to a per-interpreter GIL allows a new type of parallelism that takes advantages of the multiple core hardware in modern computers. One of these types is communicating sequential processes (CSP), which is the basis for the concurrency models in other languages like Go and Erlang.
These changes are incremental in that they don’t require any existing code to change. You can still work as you’ve always done. The PEP only opens the possibility for a new way to implement parallelism in Python.
What’s Changing in Python 3.13 (PEP 554)?
While the 3.12 subinterpreter changes involve the inner workings of the CPython program, the changes slated for 3.13 in PEP 554 will be more available for the general Python community to use. Keep in mind that the module proposed in this PEP is meant as a stepping stone to a richer and more functional API for using multiple interpreters in future versions.
Note: At the time of writing, PEP 554 hasn’t been officially accepted, so you shouldn’t view any of this information as definitive.
PEP 554 proposes adding an interpreters module to the standard library with APIs that you call directly from Python. This module will provide an Interpreter Python object as well as methods to manage these objects.
The Interpreter Object
The Interpreter object represents a Python interpreter. It has a single, read-only attribute, the .id attribute, which uniquely identifies the object.
It also provides three methods:
.is_running(), which returns a flag indicating if the interpreter is currently executing code..close(), which shuts down the interpreter. Calling this on a running interpreter will produce aRuntimeError.run(src_str), which executes the Python source in the given string.
This small API provides enough functionality to use interpreters from Python. The .run() method might seem strange at first, taking only a string as a parameter, but this, coupled with the runpy module, unlocks the door to running any arbitrary code.
You should also note that calling .run() pauses the current thread, as the proposed docstring of .run() explains:
So calling
.run()will effectively cause the current Python thread to completely pause. Sometimes you won’t want that pause, in which case you should make the.run()call in another thread. To do so, add a function that calls.run()and then run that function in a normalthreading.Thread. (Source)
You’ll see an example below that demonstrates how to do this.
The Management API
The interpreters module will also provide four functions for managing interpreters:
list_all()returns a list ofInterpreterobjects representing all the interpreters in your program.get_current()returns a single interpreter object representing the interpreter that’s currently running.get_main()returns a single interpreter object representing the interpreter that started when your program began executing.create()creates and returns a newInterpreterobject.
These APIs will provide users with the bare minimum of functionality to make use of Python subinterpreters from their Python code. The PEP lists a few other functions that this PEP omitted, mainly in order to keep the changes as small as possible.
Now you can look at how you can create and run subinterpreters.
A Threading Example
PEP 554 provides several examples of using the interpreters module. You can look at some of those and expand on them a bit, but please remember that these examples are written against a proposal to Python and do not run in current versions of Python. The code presented here is meant to give you an idea of what might be possible. It definitely won’t work in Python 3.12 or earlier, and it might need modification to run in Python 3.13.
In this example, you’ll look at how you might mix the threading module with the proposed interpreters module to demonstrate the isolation that subinterpreters provide.
In the first part of the example, you set up tools that you can use later on:
1# thread_example.py
2
3import interpreters # Proposed in PEP 554
4import threading
5# Intentionally not importing time module here
6
7def sleeper(seconds):
8 print(f"sleeping {seconds} in subinterpreter on thread {threading.get_ident()}")
9 time.sleep(seconds)
10 print(f"subinterpreter is awake on thread {threading.get_ident()}")
You can see that line 3 is importing the proposed intepreters module followed by the threading module on line 4. You then define a function named sleeper() on line 7, which is a placeholder for the code that does the work that you want to do. Note that you’re using the get_ident() function from the threading module, which returns a unique ID for the currently running thread.
Now that you have the setup, you can use interpreters without threads:
# thread_example.py
# ...
interp1 = interpreters.create()
print(f"run in main interpreter on thread {threading.get_ident()}")
interp1.run("import time; sleeper(3)") # Notice the import
print(f"return to main interpreter on thread {threading.get_ident()}")
This code makes a new interpreter with the .create() method. You then call the .run() method directly in the current thread. Note that the proposed .run() method on interpreters only takes a string argument, much like the eval() function in the standard library.
If you run this, then you’ll see something like this output:
run in main interpreter on thread 1
sleeping 3 in subinterpreter on thread 1
... a 3 second pause ...
subinterpreter is awake on thread 1
return to main interpreter on thread 1
There are a few points to notice here. First off, all of the printed thread IDs are the same, showing that a subinterpreter runs on the same thread that you call the .run() method on.
You can also see that the call to time.sleep() on line 9 in the earlier code block pauses both the main interpreter and the subinterpreter. This demonstrates that the main interpreter stops running when you call the .run() method.
Now you can spice things up and add threading to see how that works:
15# thread_example.py
16
17# ...
18
19interp2 = interpreters.create()
20thread1 = threading.Thread(
21 target=interp2.run, args=("import time; sleeper(3)",)
22)
23print(f"run in main interpreter on thread {threading.get_ident()}")
24thread1.start() # Will sleep for 3 seconds and return
25print(f"return to main interpreter on thread {threading.get_ident()}")
26thread1.join()
27print(f"finished join in main interpreter on thread {threading.get_ident()}")
This block creates another subinterpreter, then uses its .run() method as the target for the thread to run, using the same string as the previous example for its argument.
With this setup, the subinterpreter runs on a separate thread:
run in main interpreter on thread 1
sleeping 3 in subinterpreter on thread 2
return to main interpreter on thread 1
... a 3 second pause ...
subinterpreter is awake on thread 2
finished join in main interpreter on thread 1
In this example, the thread ID printed from the subinterpreter is different from the ID of the main thread. The return to main interpreter message also happens before time.sleep() finishes, showing you that the main interpreter continues running on its thread while the subinterpreter is sleeping on a different thread.
An Interpreter Persistence Example
In the previous examples, you created two different interpreters, interp1 and interp2. This is significant because calling .run() on an interpreter doesn’t clear out the previous state. This sounds unimportant, but it can have some pretty interesting consequences. In this section, you’ll see more examples exploring this property.
Again, please note that these examples are hypothetical. They won’t run in Python 3.12 or earlier, and they may not run as written in Python 3.13.
To start, you’ll make a mistake and then correct it. In a new file, continue to use the sleeper() function from the previous example:
# persist.py
import interpreters # Proposed in PEP 554
import threading
# Intentionally not importing time module here
def sleeper(seconds):
print(f"sleeping {seconds} in subinterp on thread {threading.get_ident()}")
time.sleep(seconds)
print(f"subinterpreter is awake on thread {threading.get_ident()}")
interp = interpreters.create()
interp.run("import time; sleeper(3)") # Notice the import
This time, focus on the fact that you’re not importing the time module in the main interpreter. When you ran this function in an subinterpreter before, you always included the import time; portion as part of the string for the interpreter to call. You also do that in this case for interp.
Now you can try to create another subinterpreter without that import:
# persist.py
# ...
interp2 = interpreters.create()
interp2.run("sleeper(3)") # Will throw an exception
This block is almost identical to your previous examples where you created interp. The main difference is that the string that you pass to interp2.run() no longer imports time.
Each subinterpreter is isolated from the others, meaning that its imported modules aren’t shared. Importing time in the previous interpreters doesn’t make it available in your newly created interpreter, so when you call .run() on interp2, it’ll raise a NameError because it doesn’t have access to time.
Note: Here’s where you run into a problem. The NameError object was created in the subinterpreter. You can’t use this object in the main interpreter because a different object allocator created it.
To get around this, the interpreters module wraps the exception in a new type of exception, RunFailedError. This new exception type has a property, __cause__, which holds the NameError info. This exception wrapping keeps objects like exceptions from leaking from one interpreter to another.
You already know a fix for this NameError: just import time in the string argument to .run(). But you can take another path to solve this problem.
When you call .run() on a subinterpreter, you’re not cleaning out the state of that interpreter. One way to think of this is that the string you pass to .run() is added to the __main__ section of that interpreter and runs there. All of the previous context is still present, including which modules you’ve imported.
This means you can call .run() multiple times to set up a configuration and then do some operations in the interpreter:
# persist.py
# ...
interp2 = interpreters.create()
interp2.run("import time")
interp2.run("sleeper(3)") # This will run correctly
intper2.run("sleeper(1)") # As will this
In this example, you call .run() multiple times, the first time configuring the subinterpreter with the time module and subsequent times running the actual function.
While this might seem confusing at first, it can provide some useful functionality. An example from PEP 554 describes doing an initial, long-running setup one time on an interpreter and then calling it again to process requests without the long setup each time.
A Data Exchange Example
Because each subinterpreter has its own set of objects, it’s not possible to share objects between interpreters directly. PEP 554 provides a basic mechanism for data sharing using os.pipe(). Pipes are a feature of operating systems, and they allow low-level communication. In this example, you use them to send raw data from one interpreter to another:
1# data_exchange.py
2
3import interpreters
4import os
5import pickle
6import textwrap
7import threading
8import time
9
10# Create communication pipe
11receiver, sender = os.pipe()
12
13# Set up subinterpreter
14interp = interpreters.create()
15interp.run(
16 textwrap.dedent(
17 f"""
18 import os
19 import pickle
20 """
21 )
22)
23
24def subinterpreter_function(reader):
25 data = os.read(reader, 1024)
26 obj = pickle.loads(data)
27 # Do something with obj
28
29# Start thread with subinterpreter reading data from pipe
30t = threading.Thread(
31 target=interp.run, args=(f"subinterpreter_function({receiver})",)
32)
33t.start()
34
35# Send data through the pipe to the waiting subinterpreter
36obj = {"Real Python": "realpython.com", "time": 1234}
37data = pickle.dumps(obj)
38os.write(sender, data)
This code runs a subinterpreter in a separate thread and passes data from the main interpreter to the subinterpreter:
-
Lines 3 to 8: You start by importing several standard library modules.
-
Line 11: You create a pipe using
os.pipe(). Pipes created like this are low-level primitives and require some special data handling, some of which you’ll see here. The local variablesreceiverandsenderhold the two ends of the pipe. The receiving end,receiver, will be handed to the subinterpreter when it starts. The main interpreter will use the sending end,sender, to send data. -
Lines 14 to 22: You set up a subinterpreter by creating it and then calling
.run()on it with a string that imports theosandpicklemodules. Remember that each subinterpreter has its own list of imported modules, and a newly created subinterpreter doesn’t inherit the state of the original interpreter. This step happens sequentially in the same thread. -
Lines 30 to 32: Once you’re set up, you create a new thread, using
interp.run()as its target function and having that runsubinterpreter_function()ininterpon the new thread. The value{receiver}is interpolated in the f-string to be the receiver part of the pipe returned in line 11. -
Line 33: You start the thread. Because the code in
subinterpreter_function()is running in a separate thread, you really don’t know the order in which things will happen, but assume for now that the new thread runs immediately. -
Line 25: The first thing that the new thread does is to call
os.read()on the pipe. Since nothing has been written to the pipe, this call will pause the new thread, allowing the original thread in the main interpreter to run. -
Lines 36 to 38: The original thread will then continue, creating a dictionary called
obj, pickling it on line 37 so you can send it over the pipe, and then callingos.write()to send the data on the last line. At this point, the new thread running the subinterpreter wakes up because there’s data in the pipe. -
Lines 25 to 27: You read the data and decode it using the
picklemodule. Finally, you’ve transferred the data between the interpreters, and you do something withobjto do the work in the subinterpreter.
This approach to data communication is cumbersome, but it’s possible, which is the intent of PEP 554. The authors of the PEP intentionally created the minimal viable definition for sharing data here, knowing that adding features to the language is much easier than removing them once they’re accepted.
Note: When PEP 554 ships, watch for third-party libraries to make this data interaction easier and cleaner.
These examples demonstrate how the first proposal for the interpreters module might work. This version of the module is intended as a first, hopefully solid, step to a much richer and robust set of features in future versions. If you’re interested in what future enhancements to this module might hold, then go check out the Deferred Functionality section of the PEP.
Should You Care About Subinterpreters in Python 3.12?
Even with all these changes being added to CPython for subinterpreters, few of them will have much of an impact on the average Python developer, especially in the short term.
The changes accepted for Python 3.12 could provide significant concurrency speedups for some projects, but only after extension modules make some changes to take advantage of the per-interpreter GIL. This may take a while to trickle out to the average developer, but for certain problems, this could be a huge win in the long run.
The proposed changes in PEP 554, which should come into effect for Python 3.13, are likely more interesting to the average Python developer, especially since they allow you to access this feature from Python. However, they’re really the fundamental building blocks for allowing more user-friendly access to subinterpreters.
FAQs
Here, you’ll find a few questions and answers that sum up the most important concepts that you’ve learned in this tutorial. You can use these questions to check your understanding or to recap and solidify what you’ve just learned. After each question, you’ll find a brief explanation hidden in a collapsible section. Click the Show/Hide toggle to reveal the answer. Time to dive in!
Subinterpreters are a separate, isolated version of the Python interpreter running in the same process as the main interpreter that starts when you run a Python program.
No, but they can work together nicely. Starting a subinterpreter takes over the thread in which you start it, so for many use cases, you might want to start a new thread with a new subinterpreter. A single interpreter can run multiple threads, as this is what happens in most uses of the threading module.
You can send data between interpreters using os.pipe(), but this requires serializing the data before sending it and deserializing the data after receiving it. You cannot share objects directly between interpreters.
Probably not in the short term. They’ll allow module authors to take advantage of the better parallelism available on modern hardware, but this will take a while to roll out and is likely to help with specific problems where the CPU is the bottleneck in performance.
Probably not for most developers. The interpreters module, like threading, multiprocessing, and asyncio, is a useful tool to help with specific performance issues. Just like most developers don’t throw threads into every project they write, most developers won’t use interpreters regularly. But it’ll be a great tool for those times when you need it.
These two PEPs are exciting changes, as they’ll allow significant speed improvements for some problems, and they really show the amount of work that’s going into the improvement of the language. The two changes together are a solid foundation for some really game-changing features in the future.
If you just can’t get enough of this topic and would like to see one possible higher-level API for interpreters, then you should visit the extrainterpreters project, which examines that idea with some real, albeit prototype, code.
Free Bonus: Click here to download your sample code for a sneak peek at Python 3.12, coming in October 2023.







