
In this example, we’ll connect to the Twitter Streaming API, gather tweets (based on a keyword), calculate the sentiment of each tweet, and build a real-time dashboard using the Elasticsearch DB and Kibana to visualize the results.
Tools: Docker v1.3.0, boot2docker v1.3.0, Tweepy v2.3.0, TextBlob v0.9.0, Elasticsearch v1.3.5, Kibana v3.1.2
Docker Environment
Follow the official Docker documentation to install both Docker and boot2docker. Then with boot2docker up and running, run docker version to test the Docker installation. Create a directory to house your project, grab the Dockerfile from the repository, and build the image:
$ docker build -rm -t=elasticsearch-kibana .
Once built, run the container:
$ docker run -d -p 8000:8000 -p 9200:9200 elasticsearch-kibana
Finally, run the next two commands in new terminal windows to map the IP address/port combo used by the boot2docker VM to your localhost:
$ boot2docker ssh -L8000:localhost:8000
$ boot2docker ssh -L9200:localhost:9200
Now you can access Elasticsearch at http://localhost:9200 and Kibana at http://localhost:8000.
Twitter Streaming API
In order to access the Twitter Streaming API, you need to register an application at http://apps.twitter.com. Once created, you should be redirected to your app’s page, where you can get the consumer key and consumer secret and create an access token under the “Keys and Access Tokens” tab. Add these to a new file called config.py:
consumer_key = "add_your_consumer_key"
consumer_secret = "add_your_consumer_secret"
access_token = "add_your_access_token"
access_token_secret = "add_your_access_token_secret"
Note: Since this file contains sensitive information do not add it to your Git repository.
According to the Twitter Streaming documentation, “establishing a connection to the streaming APIs means making a very long lived HTTP request, and parsing the response incrementally. Conceptually, you can think of it as downloading an infinitely long file over HTTP.”
So, you make a request, filter it by a specific keyword, user, and/or geographic area and then leave the connection open, collecting as many tweets as possible.
This sounds complicated, but Tweepy makes it easy.
Tweepy Listener
Tweepy uses a “listener” to not only grab the streaming tweets, but filter them as well.
The code
Save the following code as sentiment.py:
import json
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler
from tweepy import Stream
from textblob import TextBlob
from elasticsearch import Elasticsearch
# import twitter keys and tokens
from config import *
# create instance of elasticsearch
es = Elasticsearch()
class TweetStreamListener(StreamListener):
# on success
def on_data(self, data):
# decode json
dict_data = json.loads(data)
# pass tweet into TextBlob
tweet = TextBlob(dict_data["text"])
# output sentiment polarity
print tweet.sentiment.polarity
# determine if sentiment is positive, negative, or neutral
if tweet.sentiment.polarity < 0:
sentiment = "negative"
elif tweet.sentiment.polarity == 0:
sentiment = "neutral"
else:
sentiment = "positive"
# output sentiment
print sentiment
# add text and sentiment info to elasticsearch
es.index(index="sentiment",
doc_type="test-type",
body={"author": dict_data["user"]["screen_name"],
"date": dict_data["created_at"],
"message": dict_data["text"],
"polarity": tweet.sentiment.polarity,
"subjectivity": tweet.sentiment.subjectivity,
"sentiment": sentiment})
return True
# on failure
def on_error(self, status):
print status
if __name__ == '__main__':
# create instance of the tweepy tweet stream listener
listener = TweetStreamListener()
# set twitter keys/tokens
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
# create instance of the tweepy stream
stream = Stream(auth, listener)
# search twitter for "congress" keyword
stream.filter(track=['congress'])
What’s happening?:
- We connect to the Twitter Streaming API;
- Filter the data by the keyword
"congress"; - Decode the results (the tweets);
- Calculate sentiment analysis via TextBlob;
- Determine if the overall sentiment is positive, negative, or neutral; and,
- Finally the relevant sentiment and tweet data is added to the Elasticsearch DB.
Follow the inline comments for further details.
TextBlob sentiment basics
To calculate the overall sentiment, we look at the polarity score:
- Positive: From
0.01to1.0 - Neutral:
0 - Negative: From
-0.01to-1.0
Refer to the official documentation for more information on how TextBlob calculates sentiment.
Elasticsearch Analysis
Over a two hour period, as I wrote this blog post, I pulled over 9,500 tweets with the keyword “congress”. At this point go ahead and perform a search of your own, on a subject of interest to you. Once you have a sizable number of tweets, stop the script. Now you can perform some quick searches/analysis…
Using the index ("sentiment") from the sentiment.py script, you can use the Elasticsearch search API to gather some basic insights.
For example:
- Full text search for “obama”: http://localhost:9200/sentiment/_search?q=obama
- Author/Twitter username search: http://localhost:9200/sentiment/_search?q=author:allvoices
- Sentiment search: http://localhost:9200/sentiment/_search?q=sentiment:positive
- Sentiment and “obama” search: http://localhost:9200/sentiment/_search?q=sentiment:positive&message=obama
There’s much, much more you can do with Elasticsearch besides just searching and filtering results. Check out the Analyze API as well as the Elasticsearch - The Definitive Guide for more ideas on how to analyze and model your data.
Kibana Visualizer
Kibana lets “you see and interact with your data” in realtime, as you’re gathering data. Since it’s written in JavaScript, you access it directly from your browser. Check out the basics from the official introduction to quickly get started.
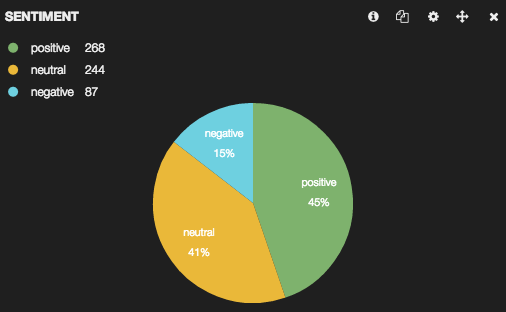
The pie chart at the top of this post came direct from Kibana, which shows the proportion of each sentiment - positive, neutral, and negative - to the whole from the tweets I pulled. Here’s a few more graphs from Kibana…
All tweets filtered by the word “obama”:
Top twitter users by tweet count:

Notice how the top author as 76 tweets. That’s definitely worthy of a deeper look since that’s a lot of tweets in a two hour period. Anyway, that author basically tweeted the same tweet 76 times—so you would want to filter out 75 of these since the overall results are currently skewed.
Aside for these charts, it’s worth visualizing sentiment by location. Try this on your own. You’ll have to alter the data you are grabbing from each tweet. You may also want to try visualizing the data with a histogram as well.
Finally -
- Grab the code from the repository.
- Leave comments/questions below.
Cheers!

